
Building a Scalable Permissions Service: Overcoming Challenges in Access Control
Permissions are at the center of every operation at Egnyte. Every interaction any user has with the system is bound to go through a stringent permission check, be it creating a file, copying it, moving it, sharing it, deleting it or using an operation as simple as adding comments. The permissions model is extremely crucial as without it, data leaks, incorrect access escalations, and unauthorized operations can occur. Given the privacy and security-centric nature of a platform like ours, the permissions module is a core component that needs to be up and running 24/7.
Egnyte is known for unparalleled flexibility and precision of permissions. However, scaling and maintaining a system with fine-grained access levels, almost instantaneous permission checks, and near real-time change propagation is a technical challenge.
Challenges of Success
As Egnyte scaled, the volume of permission entries skyrocketed, reaching millions per customer in some cases. Initially, all permission queries were handled locally on each application node, requiring a full copy of each customer's permission model to be available on every node. Over time, however, this approach began to show limitations. Although query resolution times remained stable, the memory demands of maintaining these extensive models on each node grew to be a significant bottleneck.
The issue escalated to the point where we needed dedicated application nodes solely to service our largest customers. This was necessary to avoid "noisy neighbor" effects—where high-resource users could disrupt other customers’ experiences—and to prevent performance impacts across the platform. The strain became so significant that we even listed "too many permissions" as a primary hurdle in onboarding larger customers. This setup not only drove up costs but also offset some of the efficiencies we expected at scale.
Exploration and Solution Discovery
It took a thorough research process and extensive brainstorming to identify core challenges and potential solutions. We quickly recognized that keeping the permission model in memory would necessitate a dedicated pool of servers—a specialized service dedicated solely to permissions management. Our immediate goal was to create a buffer that would allow us to develop an independent service capable of efficiently handling permissions while also forecasting potential issues we might face in transitioning to a new architecture. Fortunately, this exploration proved fruitful, yielding valuable insights and guiding us toward effective solutions.
1. Chopping the memory model
To tackle memory consumption, we launched an initiative to reduce the heap space used by objects representing the permission model. We began with simple optimizations, such as using String.intern() to ensure that frequently repeated folder and file paths in memory were stored only once.
From there, we experimented with various data structures to strike an optimal balance between performance and memory efficiency. Ultimately, we settled on a lightweight associative map structure with a load factor of 1 and an initial size of 4, allowing it to start small and expand as needed.
In filesystems, each path may comprise of characters which are not a part of the standard ASCII set we are familiar with. To ensure that operations like searching and sorting consistently work on these paths, we use their unicode normalized forms, usually referred to as canonical forms. The most significant breakthrough came when we stopped storing canonical representations of the folder and file paths internally and started computing them only as needed. This single change alone significantly reduced memory usage between 25% and 30%.
2. Tracking and addressing the largest permission consumers
Permission resolution—determining the applicable permissions for a given folder path, including inherited permissions from parent folders—is primarily used by internal processes. However, in some cases, this resolution process was being triggered repeatedly within a single customer request. When permissions were stored locally on the same server as the request-processing code, this redundancy posed minimal latency issues. However, splitting the model into different servers would cause this operation to escalate from a local to an over-the-network one, making those loops increase customer-visible latency. We applied a “measure first” approach that started by adding heavy instrumentation to determine bottlenecks and possible high-impact code and finally replacing those with more efficient bulk calls.
Key Requirements for the New Permissions Service
Designing a new permissions service demanded strict adherence to several core requirements to ensure performance and reliability on par with our existing in-memory solution.
- Ultra-Low Latency: Since every operation requires a permission check, the new service needed to operate within nanosecond-scale latency, similar to the in-memory performance of our current mechanism, to maintain a seamless experience for end users.
- High Throughput: Previously, permission checks were resolved locally within each JVM instance, making call volume less of a concern. However, with the new service supporting multiple application nodes concurrently, it had to sustain high request volumes from numerous sources without compromising speed or efficiency.
- High Availability: Nearly all operations on the Egnyte platform rely on permission checks. Consequently, any downtime in the permissions service would halt almost all interactions with the platform. To avoid such a critical point of failure, the new service had to be built with zero-downtime reliability.
Implementation
After long discussions, we implemented a solution that answered all core requirements and delivered better scalability than the previous approach.
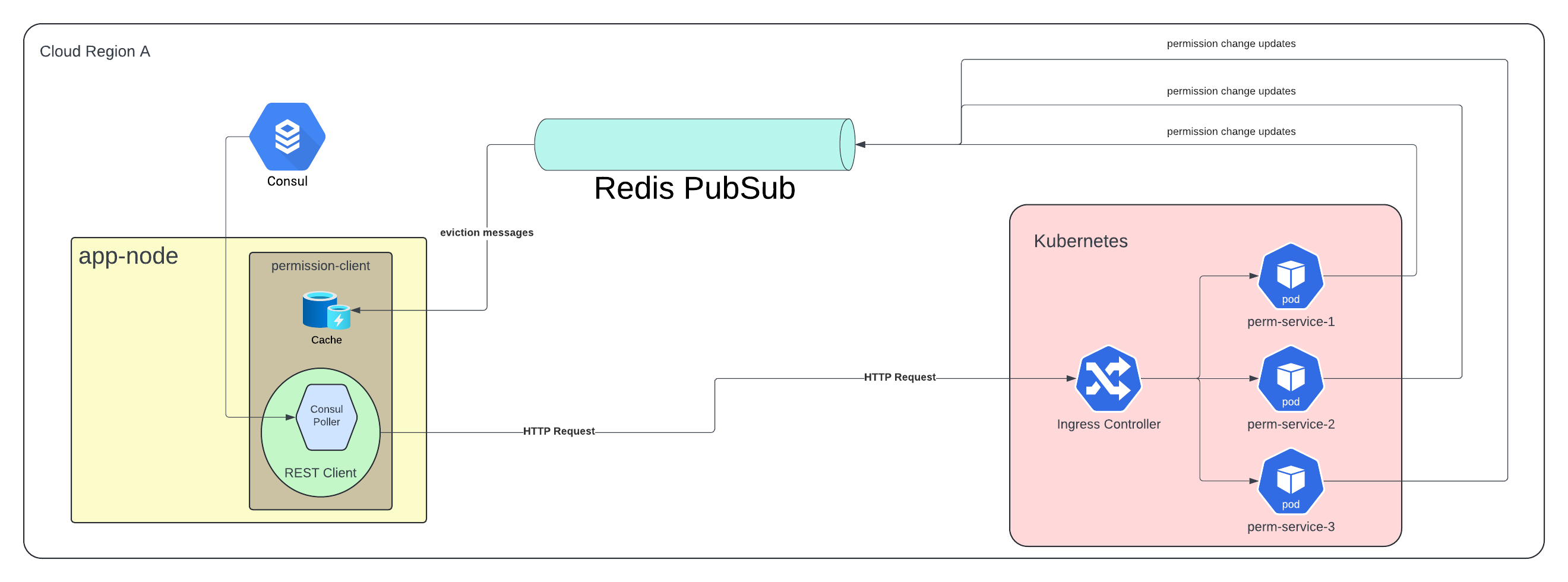
Kubernetes
We decided to take advantage of the dynamic deployment nature of Kubernetes. The platform was configured as a proactive system such that it could scale preemptively and gracefully under load. After rounds of perf tests, we concluded that scaling when CPU usage started hitting 65% was the best way to deal with load in an anticipatory manner. This addressed the availability part of the problem. This approach marked a significant improvement over our existing model wherein we had to predict the load days and weeks in advance to ensure we always had enough capacity to serve peak load and still not overdo to maintain a low cost of operations and keep the pricing low for our customers.
A “Smart” Permission Client
Along with the new service, we published an internal library we aptly named as the permission client. While this client was nominally responsible for making remote calls to the service, under the hood, we implemented a smart caching mechanism that ensured repeated calls for the same operations were cached. This cache was fine-tuned to provide fair cache space across users. The client also took care of a lot of validations and early exit cases; for example, an admin — who inherently has full access — doesn’t need permission checks. It ensured that requests that would eventually fail or always yield the same result on the remote service would instead fail fast or yield those results without ever leaving the server they originated at, saving the network round trip.
REST Client
The internal library mentioned above used a custom-built REST client, which was able to connect to a range of permissions clusters depending on the customer. We achieved this via Consul to store the client and cluster mappings and an in-house active poller to make decisions based on changes. As a result, should the need ever arise, we could always easily single out a customer to its own dedicated cluster and avoid disruptions for others.
Redis PubSub
To ensure the consumer-side cache was always up to date and never served stale data, we leveraged Redis PubSub as a signaling mechanism to evict caches. Permission changes occurring on the permission service were communicated to all the clients in real-time, with latency measuring less than a single millisecond. This helped us in addressing one of the hardest problems in Computer Science.
Execution and Rollout
Given the criticality of this service, the rollout was over a long period of time compared to other services at Egnyte. We split functions into groups based on usage frequency, patterns, expected latency, and whether they were performing reads or writes. Each group was independently ported over to the new service. In addition, we developed a proverbial ‘kill-switch’, a way to quickly restore things to the way they were, which would immediately stop routing these calls to the service and serve them locally instead, should any issue arise. Only after one group of functions was successfully ported and both synthetic tests and customer load proved that it was stable, did the rollout of the next group start. All along the process, instrumentation was in place and the application was closely monitored for any abnormalities. It took us more than half a year to complete the whole process.
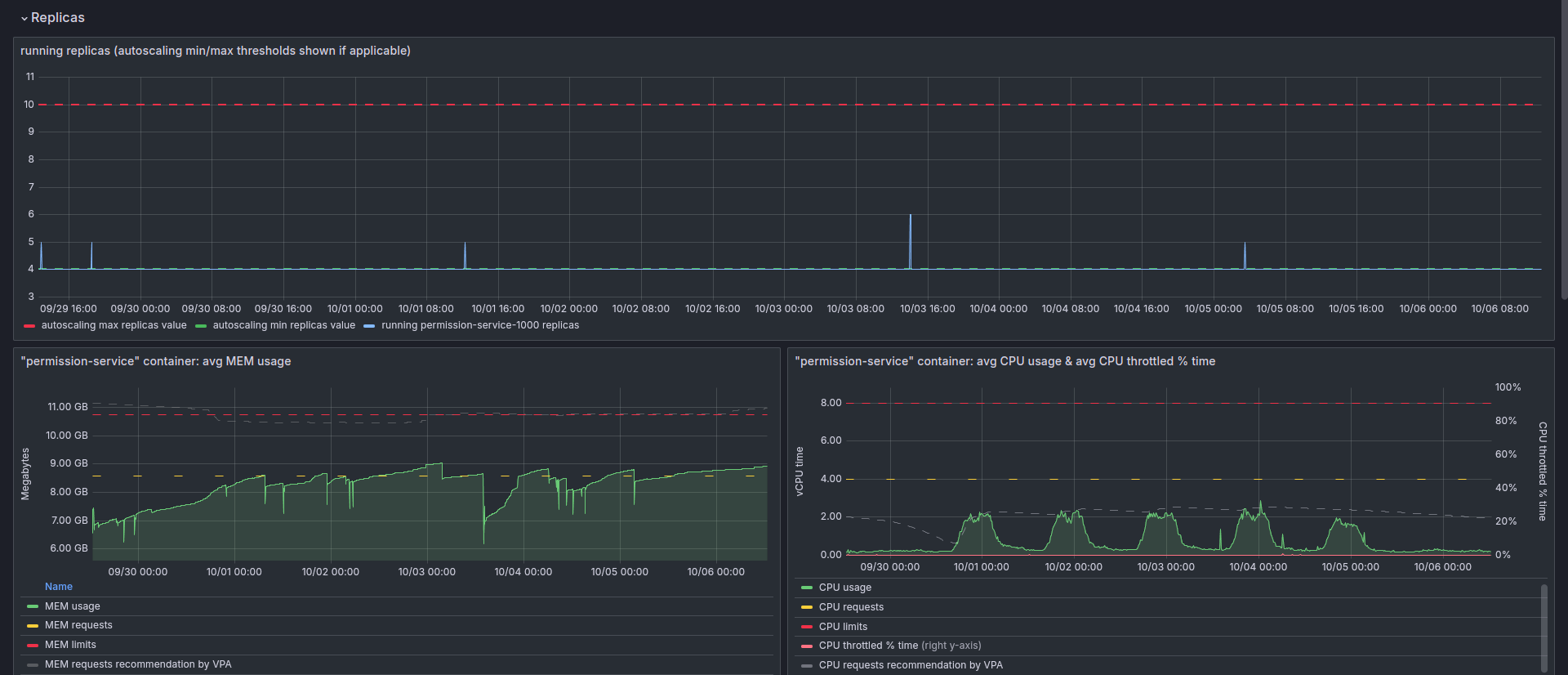
Numbers
The permission service now handles 1.10B requests per day. This is after avoiding 300M requests via the special early exit mechanisms and about 250M via the client-level caching, totaling 1.65B client calls per day.
This load is served by 32-40 instances of the service, depending on the dynamic load at any given moment. Each of the permission service containers is configured to use 4-8 vCPU and 8-10GB of RAM, out of which 6GB of RAM are allocated to the application, the rest in use by the OS.
Outcomes
The successful rollout to the new service removed the bottlenecks we faced earlier regarding the size of the permissions set. It allowed us to effectively double the number of permissions entries per customer we support. Going forward, we are now more comfortable onboarding customers with increased permission demands.
Key Takeaways
- Preparing instrumentation and metrics should be the first step before any large-scale project. The decisions to design, implement, and roll out must always be based on the data gathered rather than assumptions.
- Keep the design and architecture as simple as possible. The fewer moving parts, the lesser the friction. A simple system also provides a smaller surface area for bugs and reduces the potential tech debt. Lastly, it also becomes easier for new developers to join and work on it without spending a long amount of time understanding all the components involved.
- K8S is exceptionally powerful if correctly configured and fine-tuned to needs. Its characteristic features concerning dynamic scaling, pod affinity, and pod skewness can ensure it serves the business needs in peak hours while keeping the costs low by downscaling during periods of less usage (e.g., weekends and night hours) while maintaining low latency.
- gRPC is blazingly fast compared to REST for interservice communications, almost halving network round-trip time. However, while we tried using it, we eventually reverted back to textual representation. For large projects, it takes more than speed to drive the adoption of a technology. We had a lot of custom solutions built around traditional REST that were difficult to replicate easily in gRPC.
Next Steps
Like every new service, we started by allocating more than the required resources, so we had wiggle room and wouldn’t need to worry about getting paged for production system issues. Being stable for quite a while now, we can confidently derive the peak and non-peak loads from actual usage numbers rather than assumptions. In the near future, we aim to keep fine-tuning the cluster, combining smaller loads from multiple hosts into a single one via dynamic routing and exploring opportunities for further reduction in latency.




