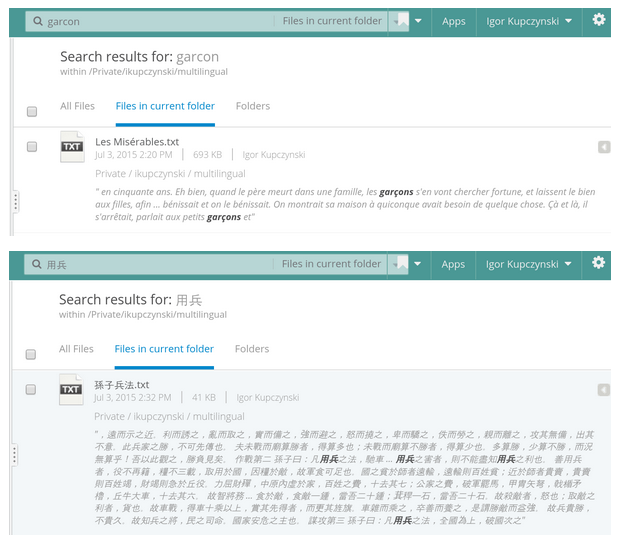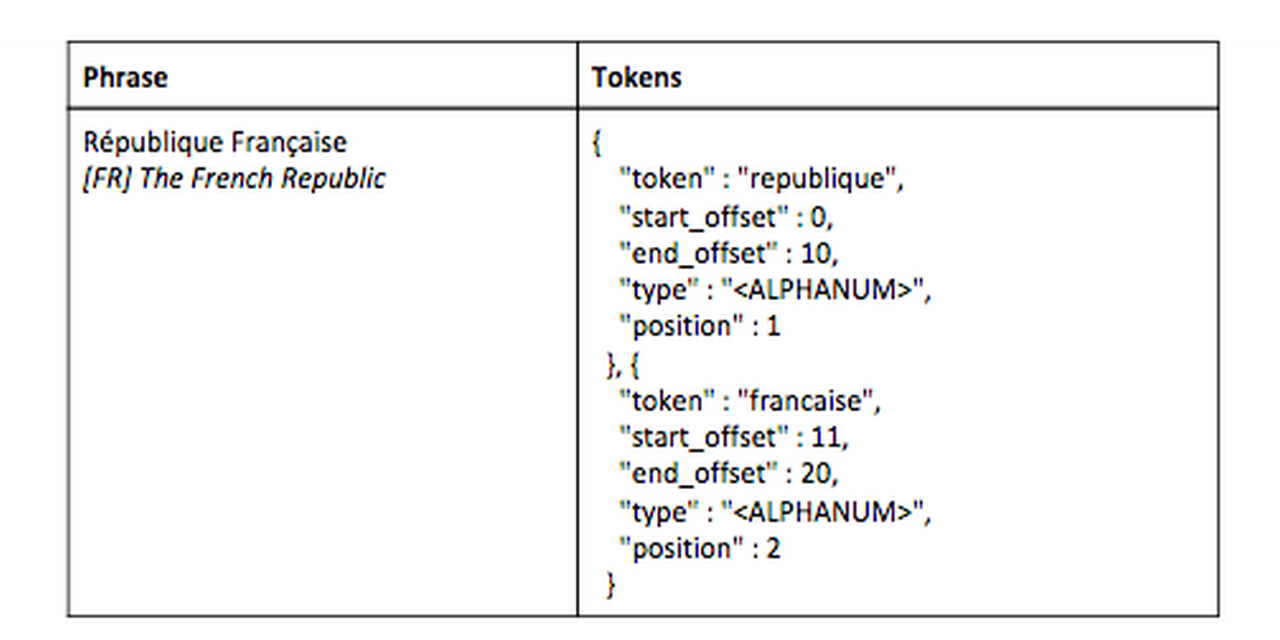
Indexing Multilingual Documents with Elasticsearch
Egnyte services all kind of companies across the globe, and we want to let our customers search for documents by phrases present in the content - be it in English, Thai, Spanish or any other language. In his latest blogpost, Kalpesh Patel described our Elasticsearch setup at Egnyte, and I will show you, in this post, how to handle multilingual documents. Implementing this is easy with Elasticsearch but requires some setup before one starts to index documents.We want to achieve the following:
- Tokenize languages that are not space delimited, e.g., Chinese, Japanese, Korean, Thai
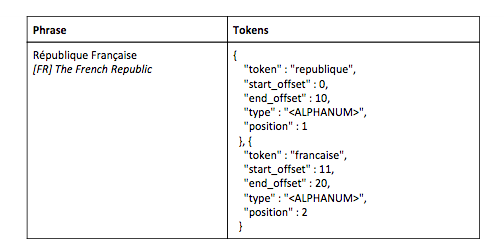
- Fold accents and national characters. This includes lower-casing the words. For example, République Française becomes republique, francaise
- Fuzzy matching
We have the following building blocks at our disposal:ICU TokenizerThis is an elasticsearch plugin based on the lucene implementation of the unicode text segmentation standard. Based on character ranges, it decides whether to break on a space or character.

ICU FoldingThis is part of the same plugin as the ICU Tokenizer. It folds the unicode characters, i.e., lowercases and gets rid of national accents.
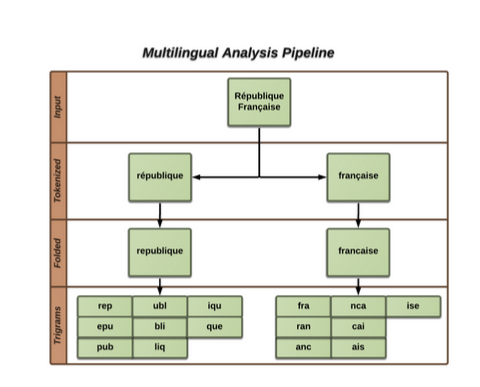
Ngrams FilterThis is the Filter present in elasticsearch, which splits tokens into subgroups of characters. This is very useful for fuzzy matching because we can match just some of the subgroups instead of an exact word match. Since ngrams are space heavy, we use them only on short, bounded fields, such as title and file name, but not on text blobs in the document content - internally we use trigrams.Example ngrams[min=2, max=5]"search" --> ["se", "sea", "sear", "searc", "ea", "ear", "earc", "earch", "ar", "arc", "arch", "rc", "rch", "ch"]Example trigrams[min=3, max=3]"search" --> ["sea", "ear", "arc", "rch"]The part of our metadata analysis pipeline dedicated for multilingual looks like this:
- ICU Tokenizer
- ICU Folding
- Trigram filter
For example, République Française will be analyzed in the following manner:
And the example mapping may look like this{"settings": {"analysis": {"filter": {"trigram_filter": {"type": "ngram","min_gram": 3,"max_gram": 3}},"analyzer": {"trigram_name_analyzer": {"filter": ["icu_folding","trigram_filter"],"type": "custom","tokenizer": "icu_tokenizer"}}}}}You need to apply this analyzer to both indexing and querying, and then you are ready to start with multilingual content in search.Full example to try is linked here.More details on multilingual analysis can be found in the elasticsearch documentation.Some examples on multilingual search with Egnyte are: