Part 2: How Egnyte Built its Turnkey Retrieval Augmented Generation Solution
In Part 1 of this series, we explored the intricacies of language models' "Retrieval" aspect, delving into how these models search and pull relevant information from vast data repositories. As we continue our journey into understanding the inner workings of language models, let’s turn our attention to the next crucial stage, "Augmentation and Generation."
In this blog post, we will explore the augmentation and generation phase, a process that is integral to the functioning of the RAG pipeline. We will cover topics such as chunk reranking, prompt construction, citations, and more. So, let's dive right into augmentation and generation in language models.
Overview of the Augmentation and Generation Process
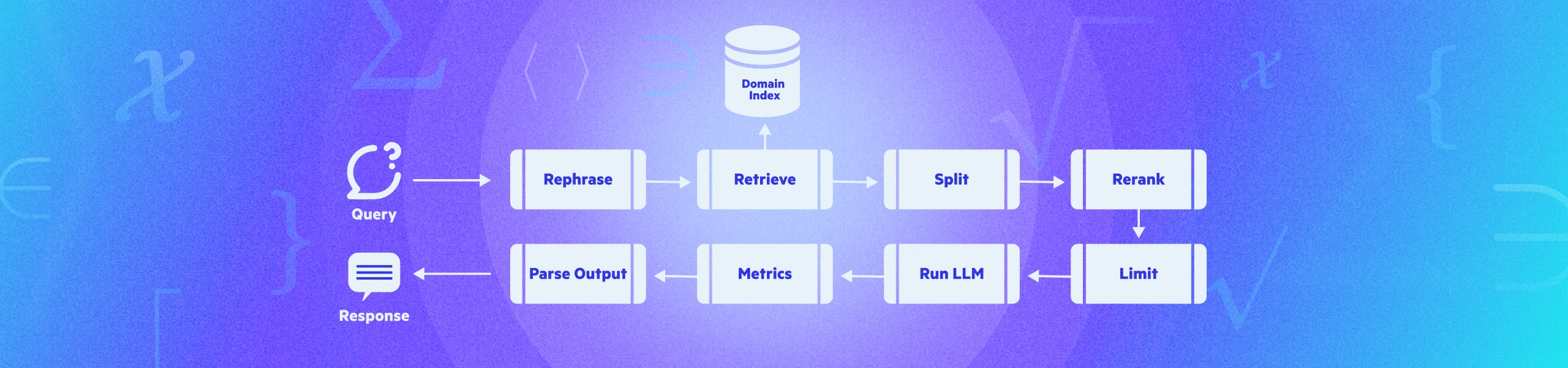
The Augmentation and Generation process in language models is a comprehensive, multi-step procedure that ensures the generation of accurate, relevant, and contextually appropriate responses. Here's a brief overview of the various stages involved in this process.
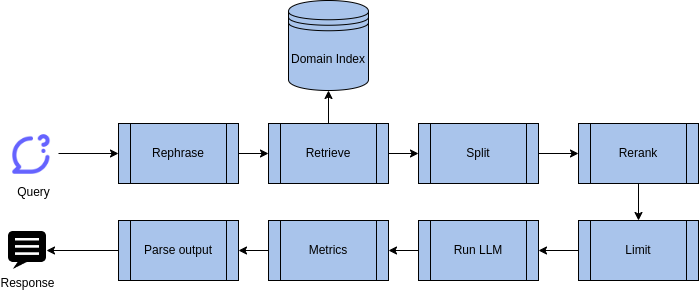
Augmentation
- Rephrase the Question: The process begins by rephrasing the original question to ensure the model understands it from various perspectives. This step helps improve the accuracy of the retrieval process (Query Rewriting for Retrieval-Augmented Large Language Models).
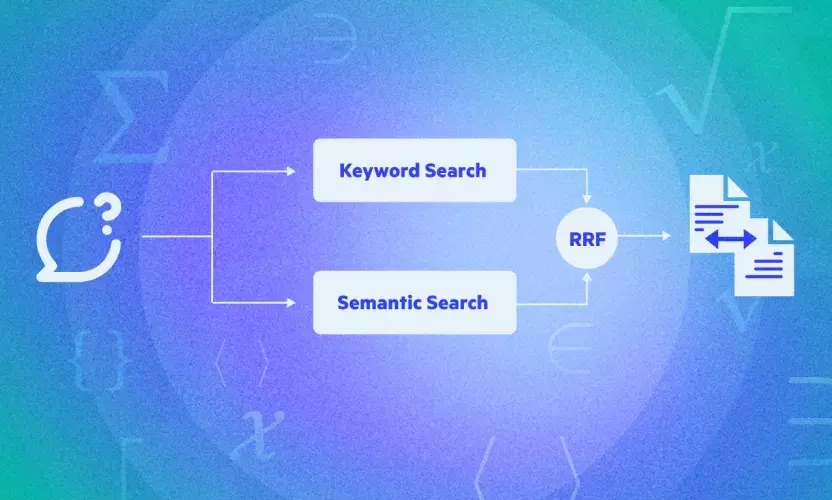
- Run Retrieval on the Rephrased Question: The rephrased question is then put through the retrieval process, which searches for relevant information from the available data repositories. The previous part of this blog series covers this.
- Split Retrieved Input into Chunks: The data retrieved is then split into smaller, manageable pieces, or 'chunks.' This step makes the data easier to handle and process in the subsequent stages.
- Rerank the Chunks Using Cross-Encoding Model: Each chunk is then reranked based on its relevance to the rephrased question. It is done using a cross-encoding model, trained to understand the semantic similarity between the question and the retrieved data (In Defense of Cross-Encoders for Zero-Shot Retrieval).
- Limit Chunks: To ensure efficiency and relevance, the process limits the chunks to the top 10 chunks based on their ranking from the previous step.
Generation
- Run the LLM: The Large Language Model (LLM) is then run on the top 10 chunks. The LLM generates a response based on its understanding of the question and the information in the chunks.
- Generate Metrics: Metrics are generated to evaluate the performance of the model. These metrics can include accuracy, relevance, and the time taken to generate a response.
- Parse the Output: Finally, the output generated by the LLM is parsed to ensure it is in a format that is easy to understand and use. This step also involves checking the output for any errors or inconsistencies.
This systematic and thorough process ensures that the language model generates responses that are not only accurate and relevant but also contextually appropriate.
Rephrase the Question
Rephrasing is a crucial first step in the augmentation and generation process of language models. It involves modifying the original question to enhance the model's comprehension and the relevance of the retrieved data. Let's delve into the specifics of this process and understand how it contributes to the overall functioning of language models.
- Insert Additional Context: The first step in rephrasing involves adding extra context to the question. For instance, incorporating today's date can provide temporal context, that will be particularly useful for time-sensitive questions or those that require up-to-date information.
- Remove Potential Harmful Parts: The rephrasing process also ensures the removal of any potentially harmful or inappropriate content from the question. This step is crucial in maintaining the ethical use of AI and avoiding any unintended consequences.
- Rephrase Similar Questions Similarly: It's essential that similar questions are rephrased in a similar manner to maintain consistency and accuracy in the generated responses. To ensure this, we have developed a specific test using a dataset of similar questions. The similarity between rephrased questions is measured using the cosine distance between their question embeddings. This technique guarantees that similar questions are rephrased closely to each other, enhancing the model's performance.
- Consider History for Follow-up Questions: The context of previous interactions is crucial when rephrasing follow-up questions. By considering the history, the model can maintain the continuity of the conversation and provide more accurate, contextually appropriate responses.
The rephrasing process, though seemingly simple, plays a pivotal role in the functioning of language models. It not only enhances the model's understanding of the question but also ensures the generation of accurate, relevant, and appropriate responses.
Splitting Retrieved Input into Chunks
Once the rephrased question has been run through the retrieval process and relevant data has been gathered, the next step in the Augmentation and Generation process is to split the retrieved input into manageable chunks. This is where the ‘RecursiveCharacterTextSplitter’ comes into play.
The RecursiveCharacterTextSplitter is a tool designed to divide the retrieved text into smaller segments, or 'chunks,' each approximately 1,000 characters in size. This size is not arbitrary; extensive testing and experimentation have shown that a chunk size of around 1k characters yields the best results in the subsequent reranking process.
Splitting the data into these chunks makes the information more manageable for the language model, enabling it to process the data more efficiently. It also allows the model to focus on smaller segments of information at a time, enhancing the accuracy and relevance of the responses generated.
Using the RecursiveCharacterTextSplitter and dividing data into 1k character chunks is a simple yet effective technique. It ensures that the language model can handle the retrieved data effectively, setting the stage for the subsequent reranking process.
Reranking Chunks Using the Cross-Encoding Model
After splitting the retrieved input into manageable chunks, the next critical step in the Augmentation and Generation process is reranking these chunks. It is done using a cross-encoding model, specifically the ms-marco-TinyBERT-L-2 model.
The ms-marco-TinyBERT-L-2 model is a compact yet powerful tool designed for the task of reranking. Despite its smaller size, it delivers impressive performance. This model was selected for the task after rigorous testing using a ground truth based on a dataset of correct chunks. The results demonstrated that the ms-marco-TinyBERT-L-2 model offers an optimal balance of speed and accuracy, making it the most suitable choice for this task.
The reranking process involves ordering the chunks based on their relevance to the rephrased question. The model evaluates each chunk and assigns it a rank based on its semantic similarity to the question.
Furthermore, to enhance the performance of the reranker, additional context is provided from the documents' metadata, such as the file name and creation date. The extra information allows the reranker to better understand the context of the chunks, leading to more accurate and relevant rankings.
The reranking process, powered by the ms-marco-TinyBERT-L-2 model, plays a crucial role in ensuring that the most relevant and accurate chunks are selected for the next stages of the Augmentation and Generation process.
Limiting Chunks
After reranking the chunks based on their relevance to the rephrased question, the next step in the Augmentation and Generation process is to limit the number of chunks that will be further processed. Given the vast variety of customer data, establishing an appropriate threshold for cutoff can be challenging. Therefore, we have decided to select the top 10 chunks for further processing.
Selecting the top 10 chunks strikes a balance between ensuring the quality of the information and maintaining efficiency in processing. These chunks, each approximately 1,000 characters in size, still fit comfortably within the context window of the Large Language Model. This size limitation also leaves room for chat history, which is crucial for maintaining the continuity and context of the conversation.
By limiting the chunks, we ensure that the LLM is provided with the most relevant and accurate information without being overwhelmed by the volume of data. This approach optimizes the model’s performance and enhances the accuracy and relevance of the responses generated.
Running the Large Language Model (LLM)
Following the limiting of chunks to the top 10, the next step in the Augmentation and Generation process is to run the Large Language Model (LLM). This stage is where the actual response generation takes place, and while it may seem straightforward, it involves a careful and strategic approach.
The process begins by creating a context from the selected chunks. It is done by 'gluing' them with unique identifiers (IDs) that allow the LLM to reference the source in citations. These IDs are crucial as they provide a way for the model to track the source of each chunk, ensuring accuracy and transparency of the information used in the response.
Our experiments have shown that short numerical IDs work better than longer identifiers such as UUIDs. The shorter IDs are easier for the model to process, leading to more efficient and accurate response generation.
Once the context is created, it’s passed to the LLM with a prompt and the chat history. The prompt guides the model in generating the response, while the chat history ensures that any follow-up questions are answered in the correct context, maintaining the continuity of the conversation.
It's important to note that the code used to run the LLM is vendor-agnostic, meaning it can work with various language model providers, offering flexibility and adaptability.
Running the LLM is a critical step in the Augmentation and Generation process. It takes the relevant, accurately ranked chunks of information and transforms them into a coherent, contextually appropriate response.
Generating Metrics
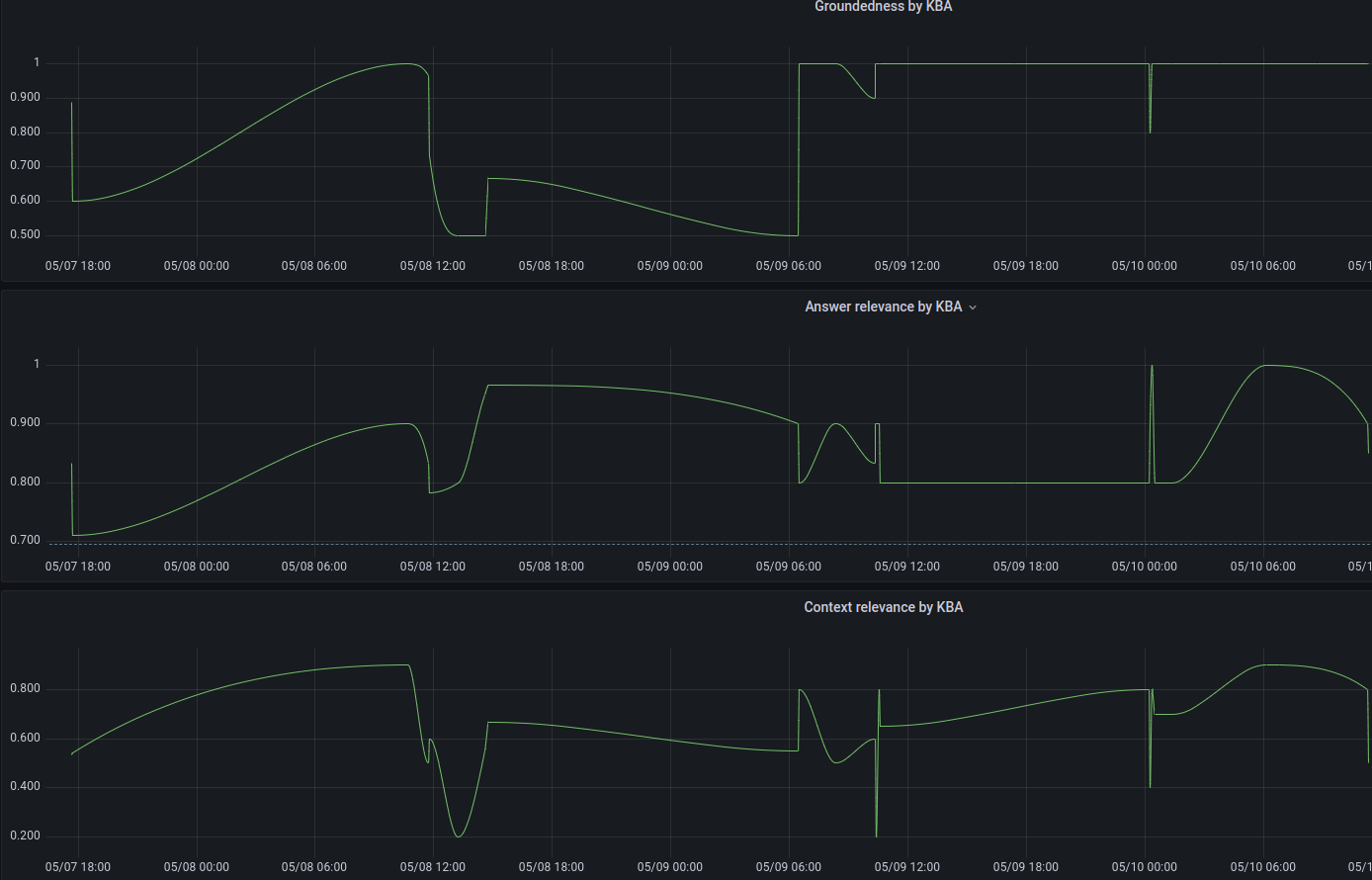
Monitoring and evaluation are essential parts of the Augmentation and Generation process, ensuring the performance and accuracy of the Large Language Model (LLM). For this purpose, we use the TruLens library, which provides a range of metrics to evaluate the model's performance.
The library offers standard Retrieval-Augmented Generation (RAG) metrics, including groundedness, context relevance, and answer relevance. These metrics provide valuable insights into the performance of the LLM, enabling us to continually refine and improve the model.
Groundedness measures how well the generated response is grounded in the information retrieved from the data sources.
Context Relevance assesses how relevant the generated response is to the context of the conversation.
Answer Relevance evaluates how relevant and accurate the generated response is to the rephrased question.
The metric generation process works on the raw inputs and outputs of the LLM. It is performed asynchronously to avoid slowing down the response generation process, as each metric requires at least one LLM call.
In addition to monitoring the overall performance of the LLM, we also monitor these metrics for each customer's datasets. This approach allows us to identify any issues with a specific dataset and engage with the customer to resolve them.
By using the TruLens library and generating these metrics, we ensure that our LLM continues to deliver accurate, relevant, and contextually appropriate responses.
Parsing the Output for User Presentation
The final step in the Augmentation and Generation process is parsing the output generated by the Large Language Model (LLM). This step is crucial to present the answer to the user in a comprehensible format and link citations to their corresponding files appropriately.
Initially, we attempted to have the LLM generate the output in a JSON format. However, this approach proved to be unreliable. The complexity and structure of JSON made it difficult for the LLM to generate consistently accurate and well-formatted responses.
To overcome this challenge, we developed our own simple, YAML-like format. This format is easier for the LLM to generate and can be parsed line-by-line, making it more manageable and stable. This approach ensures that the generated responses are not only accurate and relevant but also presented in a format that is easy for the user to understand.
The parsing process also involves linking citations in the response to their corresponding files. This ensures that the source of each piece of information is clearly indicated, providing transparency and allowing users to delve deeper into the topics if they wish.
Parsing the output is the final touch in the Augmentation and Generation process, ensuring that the responses generated by the LLM are presented to the user in a clear, comprehensible, and useful format.
Conclusion
We hope you enjoyed our deep dive into the Augmentation and Generation process in language models. Stay tuned for more insights into the fascinating world of AI and language models.