How to Introduce a New Service Efficiently Using Clean Architecture
Have you ever built a brand-new service on top of an existing bigger system? Why did you decide not to include new features in the existing system? How quickly did your team manage to implement the MVP? From a time perspective, was it a good choice? Is it possible to deliver fast and still keep good architecture and the highest code quality? I’d like to give you some insight into how we approach such challenges at Egnyte.
Our Case Study
Egnyte is a huge platform for data collaboration, governance, and security. It has multiple core features but also some industry-dedicated options to attract customers from new markets. Our Product Team introduced a vision for a brand-new solution for both existing and prospective Life Sciences customers. We knew that this project was going to be quite complex and it would have features specific to the needs of Life Sciences customers that may be too specific for the platform. We had to make a difficult decision: should we implement the new project inside the platform or make a new service from scratch? Based on where we were at the time:
- We didn’t know whether the app would succeed and pay off
- We had three months to create the MVP
- We knew that introducing a new service requires significantly more effort
- Keeping the Egnyte Platform independent from any specific industry is our company’s long-term goal, so we knew that someday we would have to do it
This was a new initiative, and we wanted to approach the Life Science market, but there were many unknowns. Could we compete with huge players that have dedicated software for Life Sciences? Are we able to implement something worth paying for in just three months? We couldn’t risk that all the effort won’t pay off because we focused on technical problems instead of important features or the project was delayed.
The decision was tough, but we found a solution: we decided to implement the MVP as part of the Egnyte Platform and later on migrate it to a new service. We were faced with a new challenge: how do we design a system where the whole infrastructure can be replaced later with no trouble and with confidence it still works the same?
Clean Architecture seemed like the perfect answer.
What is Clean Architecture?
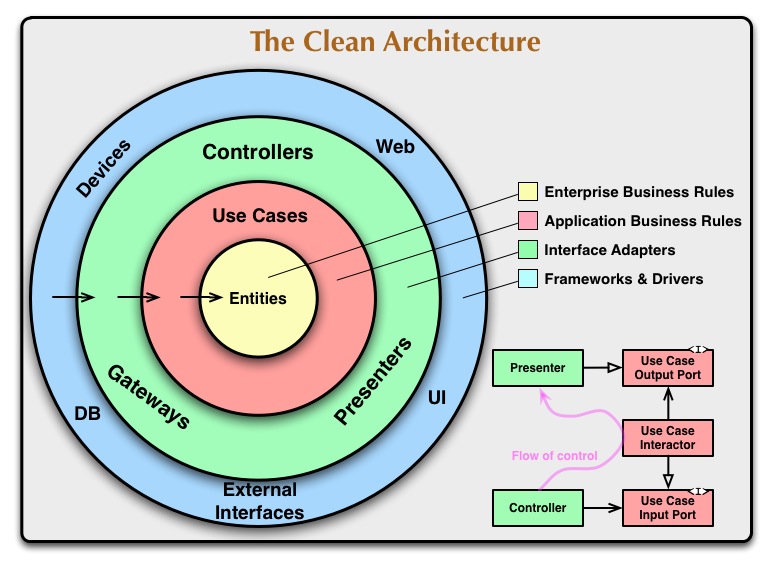
The concept was introduced by Robert C. Martin (Uncle Bob) in his blog and book (Clean Architecture: A Craftsman's Guide to Software Structure and Design). The general idea is to have core logic inside the system and all other components depending on it (not the other way around). Thanks to that, we can replace any external dependency like framework, DB, and transport protocol with whatever we want without touching business logic. Moreover, we can even replace them on the fly, use them together at the same time for the migration period or migrate components one by one in an incremental manner instead of trying to rewrite everything and deploy in Big Bang style.
Getting Started
We were sure that we had to separate all code that relies on Egnyte’s Platform so we hid it behind interfaces. We then implemented all the app logic relying only on those interfaces. Guess what—it worked! We released the MVP within three months, then another version after 3 months, and so on. We acquired some customers and our work paid off. There was only one problem: in Life Sciences, each new version of the software has to be manually validated by every customer. Naturally, they didn’t like that we were adding some new features every week (together with Egnyte’s Platform releases). Customers wanted different release cycles, in which a new version is released every three months at most. It was a perfect justification for getting more time for extracting a service from the platform. So, we came back to this idea and started to think about how to do it. It should be simple as we have already separated all moving parts, right? It wasn’t!
Let’s start with a description of how the new service stack was supposed to look like:
- Deployed in Kubernetes in Google Cloud
- Latest Spring boot + HTTP API using Spring MVC
- MySQL in CloudSQL.
How the Egnyte Platform implementation looked like:
- Deployment in tomcat on traditional VMs
- Spring 4 - no spring boot
- JAX-RS with jersey
- MySQL on VMs with JdbcTemplate and some custom transaction management and sharding
We expected to simply replace the DB layer and some Spring configuration, but it didn’t work, because:
- We had interfaces for Platform Services like FilesService, UsersService, etc. but we were using structures, DTOs, and many classes from Platform directly. For instance, class User was spread everywhere, and we couldn’t simply move it somewhere else because the whole Platform is using it, so any change there causes thousands of lines of code to change.
- We had all code in a single maven module where we had both interfaces and their implementations.
- We used Platform testing infrastructure to implement integration tests also in the same maven module.
If at First, You Don’t Succeed. . .
We took a step back and fixed our implementation by applying Clean Architecture patterns in the right way this time. To do this, we divided our work into several stages:
Stage 1: Correct Clean Architecture Within the Egnyte Platform Implementation
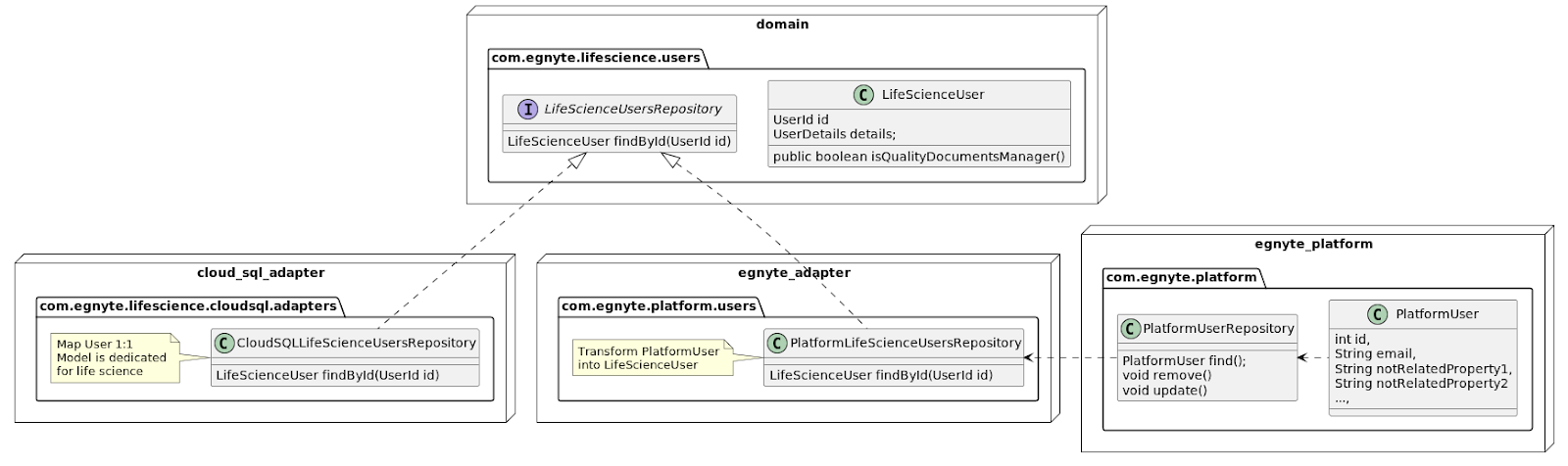
1. We replaced all usage of the platform’s classes with our domain-specific ones, which are more suitable and much smaller. For example, we don’t need a full User class – it’s enough to have an ID, name, email, and a few others. Also, we could add more customized methods to our versions of some common classes.
Here’s how it looked in practice:
- The domain model uses the "PlatformUser" class from Egnyte Platform. It has dozens of fields that we don't need in our app
- We introduced our version of the user class - "LifeScienceUser" that contains only what we need. We even added some specific methods to it
- Users appear in many places within the app so to avoid many HTTP calls to the Egnyte Platform we copy users to our database. To do that, we use delta API and a cyclic job that fetches all changes
We also created an interface "LifeScienceUsersRepository" with some methods for user fetching. "LifeScienceUsersRepository" has two implementations:
- "PlatformLifeScienceUsersRepository" - it gets "PlatformUser" from "PlatformUsersRepository" and converts it to "LifeScienceUser." It is implemented in the egnyte_adapter module (see below)
- "LifeScienceUsersRepository" - it gets "LifeScienceUser" from the app's CloudSQL database (see below)
"LifeScienceUser" is then used in the domain module instead of "PlatformUser."
2. We introduced Interface Adapters that translate objects between platform and our domain.
3. Lastly, we moved all platform-related code into a separate maven module leaving only interfaces in the core module.
Stage 2: Create a New Service
1. Create a new code repository
2. Implement a service based on spring boot
3. Set up a Kubernetes deployment
4. Configure CloudSQL DB
Stage 3: Move Core Code to a New Repository
1. Move the maven module with the whole core logic to the new repository
2. Import core logic as a maven dependency in the Egnyte Platform
Stage 4: Migrate DB
1. Implement repositories adapters for CloudSQL - another maven module in the new repository
2. For the migration period, use both maven modules with repository adapters in the Platform with the possibility to change them dynamically using feature flags. More precisely, we had two implementations of each repository interface in the class path. We defined the primary bean which was a dynamic Proxy containing both implementations and a feature flag that decides which implementation system should use
3. Disable all writes for a while to give our DBAs time to migrate data from Platform MySQL DB to our CloudSQL instance. We had a short maintenance window for that
4. Once data is migrated, get rid of previous repository implementations
Stage 5: Migrate Features
1. In our app, features are implemented in layers, so we could start the migration of the first layer (basic features) that has the least dependencies and move down layer by layer, implementing required adapters once it was needed
2. Thanks to feature flags, we can switch traffic to the new service dynamically on the endpoint level. So we can switch only those endpoints that were already fully implemented in the new service
3. Implementation in the new service requires implementing all missing adapters (HTTP clients and Spring Rest Controllers)
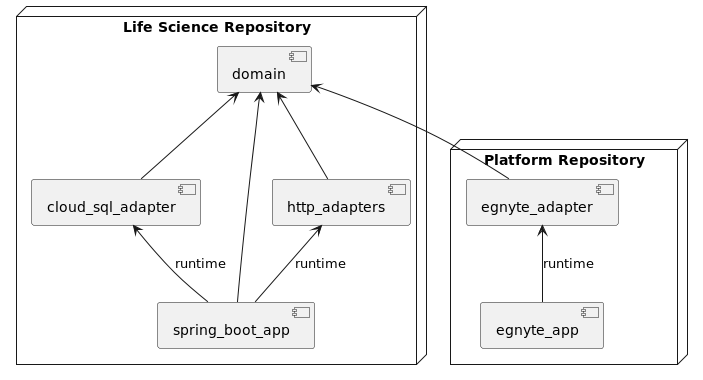
Our component structure (maven modules) looks like this:
These modules can be mapped to Clean Architecture layers:
- domain - contains both Entities and Use Cases. Keeping Entities in a separate module makes sense when we want to share some basic business rules with other apps without specific Use Cases. In our case, it’s very unlikely to happen. Still, this module has no dependencies on any infrastructure - it’s pure java code.
- cloud_sql_adapter - Interface adapters for DB. Contains implementations of Repositories.
- http_adapters - Interface adapters for Egnyte Platform HTTP API. Contains implementations of Gateways based on HTTP clients.
- spring_boot_app - Interface adapters for HTTP Controllers and Framework. Contains Spring Rest Controllers and glue code to make everything work together.
- egnyte_adapter - contains implementations of Repositories, Gateways, and Controllers. This project is only temporary so it doesn’t make sense to divide it into many modules.
- egnyte_app - Egnyte Platform just includes egnyte_adapter, so our Life Science app can still be part of the platform.
Conclusion
Clean Architecture opens many options for changing any moving parts of the system in a controlled and safe manner. Moreover, it enables us to move a massive amount of code to a new repository without code duplication, so we avoid all trouble of keeping two repositories in sync manually. Another significant advantage is that we can start with a simple adapter implementation to meet the deadline and then replace it with a better-performing solution later. Of course, Clean Architecture requires the team to learn the idea first. It might be challenging initially, but once the team gains traction on how it works, it becomes much easier to work with and maintain. We didn’t cover testing in this system, but we’ll cover that in an upcoming post.