Part 1: Audio/Video Search @ Egnyte
At Egnyte, close to 7 Terabytes of Audio/Video(A/V) data is uploaded per day by our customers. As of now, we have close to 12 Petabytes of A/V content at rest, and it’s growing continuously, forming about 18% of the total content on the Egnyte platform. This is a two-part blog series where we discuss in-depth how we index and search A/V content.
We are at the forefront of making the A/V experience remarkable for our customers with features such as:
- Video Transcoding capabilities to optimize viewing across different platforms and devices.
- Native support for videos with dedicated video player capability, so you can watch videos from the browser itself via the Egnyte website.
- Customized home-built tech to support content caching and faster range requests.
- Search enhancements so you can find your favorite/important content quickly.
- Summarizations and Q&A with the file.
To further improve the Audio/Video(A/V) experience, Egnyte has added A/V search and transcription capabilities. Now, you can search for your A/V content like a regular text search. Further, you can download the transcript in a WebVTT format.
The idea for reimagining the video experience was mooted during one of our internal hackathons, where we implemented the first working Proof of Concept(POC). It was further refined with inputs from brainstorming sessions to arrive at an end-user-acceptable solution.
New Features:
- Ability to search A/V content like regular text.
- Ability to download transcripts.
These features allow users to easily find and retrieve desired content from their large content library. With timecodes in the transcript, they can quickly jump to the right destination within the audio/video file.
Tech Design:
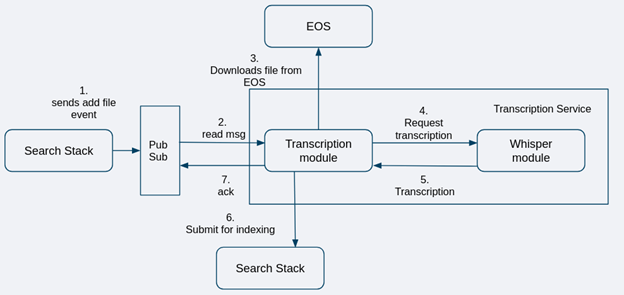
Components:
- Search Stack: It comprises Elasticsearch and our in-house apps that manage our interactions with search.
- Pub/Sub: It’s used to get asynchronous processing.
- Egnyte Object Store (EOS): It handles the object lifecycle for all customer data.
- Transcription Service: A dedicated service that listens to Pub/Sub, downloads the file from EOS, processes it, and then sends the transcription back to the search. It has two modules:
- Whisper module: A general purpose open source automatic speech recognition (ASR) model. This module processes the A/V content and generates its transcription.
- Transcription module: It is the management layer that handles all tasks like interacting with various components including Search, Pub/Sub, and EOS, and activities like error handling, retries, monitoring, metrics, etc.
Flow:
- When a new A/V file gets uploaded to Egnyte EOS, the Search Stack processes it and indexes the basic metadata.
- It then sends an event over Pub/Sub to the transcription service.
- The transcription service then downloads the file from EOS and, using Whisper, processes the file to generate the transcription. This transcription is then sent back to search for indexing to make it searchable.
The team researched the available industry solutions and found Whisper as the solution that meets our requirements the best.
Infrastructure:
We run our stack on Kubernetes and support processing on both CPU and GPU pools. We rely heavily on spot instances to save costs. CPU-based pools are used to augment GPUs in case of capacity issues. We make use of Horizontal Pod Autoscaling (HPA) with metrics from our Pub/Sub to scale, based on the current backlog.
Considerations:
We have limited the file size eligible for processing to 500 MB for videos and 100 MB for audio basis stats. This covers 95% of A/V content uploaded to Egnyte. For “Whisper” we are using the small model as we found it fits our requirements for now.
Testing:
We strictly recommend and follow Test Driven Development (TDD). Since Pub/Sub is the pipeline's starting point, Egnyte spins up a Pub/Sub emulator, which provides local emulation of the production Pub/Sub service. Though the capabilities of the emulator are limited, it still serves the purpose of integration testing.
Performance Testing:
We ran tests for both CPU and GPU platforms. For each, we added about 40K messages to Pub/Sub in our staging environment to test the performance. We disabled HPA and configured it to run with 30 replicas for CPU and 15 replicas for GPU. The test results were satisfactory for our requirements.
Monitoring:
At Egnyte, we are firm believers in observability. For the A/V transcription service, we capture many important metrics that help us analyze and evaluate the performance of the service better.
Some of the important ones are:
- Pub/Sub Backlog;
- Messages - Processed / Acknowledged / Inflight / Skipped;
- Error Details (No Audio, Corrupt File, Transient failure, and Transcription error);
- Transcription Lag (measures the time from file upload to transcription availability);
- Transcription Size;
- Audio Length, Transcription Time, and Total Time;
- Total Audio Length Processed, Total Size Processed (GB), and File Type by Extension.
Next Steps:
Transcription opens up other interesting possibilities such as:
- Evaluate the use of transcriptions as video subtitles.;
- Serve transcriptions in multiple languages;
- Speaker diarization.
These ideas may be useful for another hackathon!
Share this Blog
AUTHOR