



Featured Resource














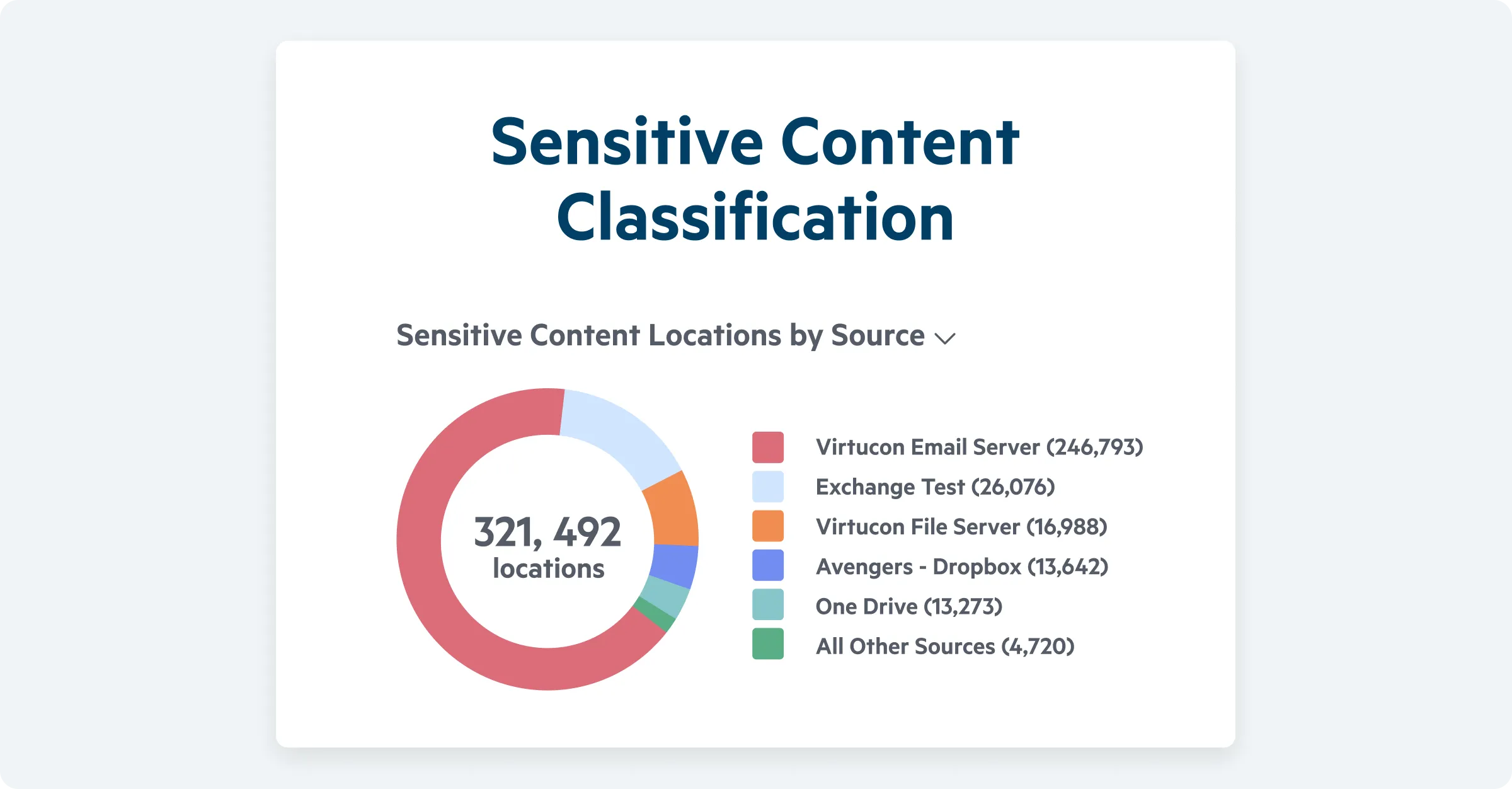
Get a clear, real-time view of where sensitive content lives across your data repositories, so you can assess risk instantly, act on exposed data, and stay aligned with your most critical compliance requirements.
Go beyond visibility to understand risk at the file level. See how many sensitive files exist across folders and subfolders, prioritize protection with clear risk scores, understand applicable cybersecurity and privacy regulations, and identify exactly who can access your most sensitive data.
Turn insight into enforcement. Apply data-sharing policies based on content type, risk score, and location in minutes, restrict sharing to authorized users, while supporting flexible exceptions that match your business needs.
Continuously monitor sensitive content subject to cybersecurity and data privacy regulations such as PCI-DSS, GDPR, CPRA, and SOX. Reduce manual workloads with automated labeling, prioritize content with the highest exposure risk, and enforce content classification policies that align with business requirements.
Protect sensitive, mission-critical data across your IT environment while reducing exposure risk.

“The biggest business accomplishment is the efficiency of freeing up IT resources. Without having to do the labor-intensive work of identifying sensitive content, IT can now concentrate on value-add projects.”
Want to see what Egnyte has for your organization?
Sensitive Data Protection is part of Egnyte’s governance platform. Enhance content protection with these complementary products.
Have more questions? Contact Sales to get the answer you’re looking for.
Sensitive content is any information that could cause a financial and/or reputational loss to an organization if it’s not adequately protected. It includes:
Sensitive content classification helps organizations identify Personally Identifiable Information (PII), Protected Health Information (PHI), and financial data, which are frequently impacted by regulatory compliance requirements.
Yes. Egnyte helps organizations identify sensitive content across multiple data platforms and perform classification of sensitive information in those repositories.
Sensitive data classification is a foundational component of a broader data governance program. It works alongside complementary capabilities such as ransomware detection, insider threat detection, and regulatory compliance to help organizations manage and protect data holistically.
Sensitive content classification is applicable for all industries and is mission-critical for organizations in financial services, life sciences, legal, and defense.
Companies that don’t pursue confidential data classification programs face extreme risk including:
Yes, classification of sensitive information can be performed with AI-powered data governance platforms like Egnyte.
Ready to improve productivity? Egnyte’s AI-powered cloud enhances collaboration, automates workflows, and secures your mission-critical content.


